Awesome.
Friday 25 September 2009
Wednesday 3 June 2009
Using CruiseControl.rb to manage a Perl Catalyst project
We're working with the Catalyst framework again, porting an old Perl 5 HTML::Mason site to Catalyst and introducing some modern Perl coding standards to a fairly old stack.
One of the things we needed was a Continuous Integration tool for the project. Since we're already using CruiseControl.rb for the Rails projects I thought it should be pretty easy to incorporate the Perl project into it.
And indeed it was:
$ ./cruise add CatalystProject --url https://svn.work.com/svn/catalystproject/trunk/
CruiseControl will run a "rake" task whenever a commit is made. So we need a small Rakefile with just enough code in it to run the standard Perl tools:
$ cat Rakefile
require 'rake'
task :default => :test
desc "Runs make test"
task :test do
t = system("eval $(perl -I$HOME/perl5/lib/perl5 -Mlocal::lib) && perl Makefile.PL && make test")
rc = $?
puts "\nMake finished with t=#{t} rc=#{rc.exitstatus}"
raise "Perl make failed (rc=#{rc.exitstatus})" unless t
end
task :default => :test
desc "Runs make test"
task :test do
t = system("eval $(perl -I$HOME/perl5/lib/perl5 -Mlocal::lib) && perl Makefile.PL && make test")
rc = $?
puts "\nMake finished with t=#{t} rc=#{rc.exitstatus}"
raise "Perl make failed (rc=#{rc.exitstatus})" unless t
end
The eval line in the system call is there because we're using local::lib to manage our Perl library dependencies and we need to set the environment variables so that they can be found. To propagate any "make test" errors back out to rake we throw an exception on non-zero exit codes.
Tuesday 12 May 2009
How to set your DNS search list in OSX
Here's how to set your DNS search path in OSX, which is something you'll want to do if you're getting redirected to eBay when you try to go to Google, or are experiencing other odd behaviour from your browser.
- Open System Preferences.
- Open Network settings.
- Your active network connection should be selected on the left. Select it if it is not. Click the "Advanced" button towards the bottom right hand corner.
- Select the DNS tab.
- On the right hand side is a column "Search Domains." It will probably already have your domain name listed, but it will be "greyed" out so that you can't remove it. That's OK. Click the "+" sign at the bottom of the column, and type the domain name again.
- You should now have the domain name listed twice. One will be grey, the other black. This is good, believe it or not. :-)
- Click OK.
- Click Apply.
Thursday 7 May 2009
The "search path fix" for ASZ.COm.Au is only a partial fix
Feel I need to clarify my fix to the "eBay/ASZ redirection problem" discussed in my last post.
Adding your domain name to your DNS search path will stop your DNS resolver from asking the "au.com.au" and "com.com.au" name servers for "google.com.au.com.au". So you shouldn't get "Welcome to ASZ.COm.Au" or be redirected to eBay or other unexpected behaviour.
What you'll get instead is "site not found". That's what I mean by a partial fix. If your ISPs name server is losing DNS responses (or is too slow to return them) then you'll still have problems: namely you'll get an error message when you try and visit some sites. However clicking "Refresh" or "Reload" will generally solve that problem. Once your at the site the address will be in your resolver's cache so things will be stable for a while.
Meanwhile I've written to the auDA guys asking for their opinion on defining DNS entries for other peoples domain names as sub-domains of yours.
Adding your domain name to your DNS search path will stop your DNS resolver from asking the "au.com.au" and "com.com.au" name servers for "google.com.au.com.au". So you shouldn't get "Welcome to ASZ.COm.Au" or be redirected to eBay or other unexpected behaviour.
What you'll get instead is "site not found". That's what I mean by a partial fix. If your ISPs name server is losing DNS responses (or is too slow to return them) then you'll still have problems: namely you'll get an error message when you try and visit some sites. However clicking "Refresh" or "Reload" will generally solve that problem. Once your at the site the address will be in your resolver's cache so things will be stable for a while.
Meanwhile I've written to the auDA guys asking for their opinion on defining DNS entries for other peoples domain names as sub-domains of yours.
Thursday 30 April 2009
Welcome to ASZ.COm.Au (Or, The Resolver Library is Broken)
A few days ago, I did a Google search and got the strangest error: a 404 (File Not Found) page that claimed to be from Apache with PHP and Frontpage extensions loaded. Google doesn't run Apache.
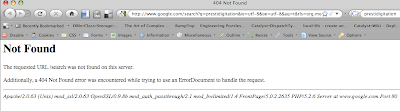
Since that was A Very Odd Thing Indeed I went to the Google home page. This time I got a new message: "Welcome to ASZ.COm.Au" (for some reason, I feel it's important to preserve the capitalisation).
 My first guess was that my DNS cache had been poisoned. Or that I'd picked up a virus somehow. When I looked on Twitter I saw that I was not alone: a few people were reporting similar problems trying to access Facebook, YouTube, Google and even eBay. A discussion about the issue had started on Whirlpool. In most cases, the issue appeared to resolve itself eventually, or after a DNS cache flush.
My first guess was that my DNS cache had been poisoned. Or that I'd picked up a virus somehow. When I looked on Twitter I saw that I was not alone: a few people were reporting similar problems trying to access Facebook, YouTube, Google and even eBay. A discussion about the issue had started on Whirlpool. In most cases, the issue appeared to resolve itself eventually, or after a DNS cache flush.
In my case, the issue persisted for a little while and then stopped. I was able to access Google again.
It took some time for me to figure out what was going on (hey -- I'm over 27). The intermittent nature of the issue made debugging difficult. It wasn't until my partner mentioned that she'd seen the same screen when she'd tried to access the Bureau of Meteorology that I was able to make progress. Visiting http://bom.gov.au/ (but not http://www.bom.gov.au/) consistently reproduced the problem.
I chased down a few theories: malware, cache-poisoning, an "optus issue". But I finally worked out that this was the result of a documented feature of the common UNIX resolver library.
When you visit a web page your computer needs to "resolve" the host name (eg "google.com.au") to an Internet address. That's the job of the resolver, which in turn uses something called a domain name server. Your browser asks the resolver "what's the address of Google.com.au" and the resolver answers. Either the resolver already knows the answer because it's looked it up before and kept a copy (a cache), or it doesn't know, and so it asks the domain name server. The domain name server in turn may ask other domain name servers, until someone, somewhere, knows the answer. The answer is then sent back through the chain, ultimately to your resolver (called the "client").
So if the resolver doesn't know an address it asks the domain name server and waits for an answer. But it will not wait forever. In fact, it typically won't wait longer than several seconds. It's an impatient little thing and if it hasn't heard back quickly enough it assumes that maybe the hostname is wrong -- maybe the user just typed part of the hostname. Or maybe the domain name server does answer in time but the resolver cannot use the answer -- the domain name server may reply with "no one knows that hostname." Either way, the resolver will start to guess what the real (or "fully qualified") hostname might be.
There are two strategies a resolver can use when it starts searching for the fully qualified hostname.
The first is to use an explicit list of search paths. You usually provide this list yourself when configuring your network settings. If you haven't set such a list, then it will employ the second strategy. (That's going to turn out to be quite handy...)
The second thing your resolver can do is a "domain name search". It takes your domain name, prepends the hostname you're looking for and does a lookup on that. I'm with Optusnet, so my domain name is "optusnet.com.au". My reslover then might lookup "bom.gov.au.optusnet.com.au" if it doesn't get a useful answer for "bom.gov.au". If it still doesn't get a useful answer (and it this case, it won't) then it starts searching "up" the domain name -- it removes the first part of the domain name and repeats the search. So its second search is for "bom.gov.au.com.au". See what it did there? It deleted "optusnet" and tried again. (Technical note: the behaviour is documented in the resolver man page -- see RES_DNSRCH)
That right there is the flaw and the root cause of the problem.
Someone owns the domain names "au.com.au" and "com.com.au". And they have name servers. And they've set them up to answer queries for a whole host of things, among them, bom.gov.au.com.au, google.com.au.com.au and facebook.com.com.au. And our resolvers are querying them and merrily sending our browsers there if the real name servers for those domains don't get their answers back in time.
Now we know enough to say what's going on:
There's a fix though, which at least works on OSX (Mac). If you set an explicit search path, then the resolver won't use the second strategy described above. It will search the search path(s) and then stop there. I've set my search path to "optusnet.com.au", the same as my domain name, and can no longer reproduce the problem.
There are other things that can help:
Other things can be explained:

Since that was A Very Odd Thing Indeed I went to the Google home page. This time I got a new message: "Welcome to ASZ.COm.Au" (for some reason, I feel it's important to preserve the capitalisation).

In my case, the issue persisted for a little while and then stopped. I was able to access Google again.
It took some time for me to figure out what was going on (hey -- I'm over 27). The intermittent nature of the issue made debugging difficult. It wasn't until my partner mentioned that she'd seen the same screen when she'd tried to access the Bureau of Meteorology that I was able to make progress. Visiting http://bom.gov.au/ (but not http://www.bom.gov.au/) consistently reproduced the problem.
I chased down a few theories: malware, cache-poisoning, an "optus issue". But I finally worked out that this was the result of a documented feature of the common UNIX resolver library.
When you visit a web page your computer needs to "resolve" the host name (eg "google.com.au") to an Internet address. That's the job of the resolver, which in turn uses something called a domain name server. Your browser asks the resolver "what's the address of Google.com.au" and the resolver answers. Either the resolver already knows the answer because it's looked it up before and kept a copy (a cache), or it doesn't know, and so it asks the domain name server. The domain name server in turn may ask other domain name servers, until someone, somewhere, knows the answer. The answer is then sent back through the chain, ultimately to your resolver (called the "client").
So if the resolver doesn't know an address it asks the domain name server and waits for an answer. But it will not wait forever. In fact, it typically won't wait longer than several seconds. It's an impatient little thing and if it hasn't heard back quickly enough it assumes that maybe the hostname is wrong -- maybe the user just typed part of the hostname. Or maybe the domain name server does answer in time but the resolver cannot use the answer -- the domain name server may reply with "no one knows that hostname." Either way, the resolver will start to guess what the real (or "fully qualified") hostname might be.
There are two strategies a resolver can use when it starts searching for the fully qualified hostname.
The first is to use an explicit list of search paths. You usually provide this list yourself when configuring your network settings. If you haven't set such a list, then it will employ the second strategy. (That's going to turn out to be quite handy...)
The second thing your resolver can do is a "domain name search". It takes your domain name, prepends the hostname you're looking for and does a lookup on that. I'm with Optusnet, so my domain name is "optusnet.com.au". My reslover then might lookup "bom.gov.au.optusnet.com.au" if it doesn't get a useful answer for "bom.gov.au". If it still doesn't get a useful answer (and it this case, it won't) then it starts searching "up" the domain name -- it removes the first part of the domain name and repeats the search. So its second search is for "bom.gov.au.com.au". See what it did there? It deleted "optusnet" and tried again. (Technical note: the behaviour is documented in the resolver man page -- see RES_DNSRCH)
That right there is the flaw and the root cause of the problem.
Someone owns the domain names "au.com.au" and "com.com.au". And they have name servers. And they've set them up to answer queries for a whole host of things, among them, bom.gov.au.com.au, google.com.au.com.au and facebook.com.com.au. And our resolvers are querying them and merrily sending our browsers there if the real name servers for those domains don't get their answers back in time.
Now we know enough to say what's going on:
- You try and visit Google, Facebook, Twitter (or the BoM). It's been a while so the address isn't in your resolver's cache. So it does a lookup by asking your domain name server -- this is usually provided by your ISP.
- For whatever reason, your ISP's name server is either too slow to respond or the response is lost altogether. So your resolver "times out" and starts to "search". Your domain name ends in ".com.au" and so eventually, your resolver looks up "google.com.au.com.au" (or whatever site you're trying to visit, with ".com.au" added to the end). The name servers at "au.com.au" (or "com.com.au" depending on what you're looking up) do respond and do so in time.
- Your resolver gives the bogus address to the browser and stores it in the DNS cache. The "TTL" (time to live) for those addresses is 4 hours, so you're going to be stuck with that address in your cache for at most 4 hours.
- Eventually, your cache times out. Or maybe you know how to flush it. Either way, a second attempt by the resolver to get the right IP address works and the problem appears to be resolved.
- The ISPs name server is either too slow to respond or perhaps "dropping" packets (DNS packets are typically using UDP which is not a guaranteed delivery mechanism like TCP). I've seen this with Optusnet before but in the past I just got a "site not found". Such responses aren't cached so if you hit "Refresh" in your browser you typically find the site just fine the second time.
- The name servers for "com.com.au" and "au.com.au" have records that match other peoples sites. They shouldn't. Right now, it's just confusing and annoying but its potential for phishing is obvious. It's not necessarily malicious but it should be changed.
- The algorithm used by the resolver in both UNIX and Windows has a security flaw: it should not search all the way back to ".com.au".
There's a fix though, which at least works on OSX (Mac). If you set an explicit search path, then the resolver won't use the second strategy described above. It will search the search path(s) and then stop there. I've set my search path to "optusnet.com.au", the same as my domain name, and can no longer reproduce the problem.
There are other things that can help:
- If your ISP's domain name server is not reliable use OpenDNS. There is some anecdotal evidence that the possibility of DNS replies being late or dropped is lower. Getting the "Welcome to ASZ.COm.Au" page for Google or Facebook depended on your computer not getting the DNS response in time (or at all) so having a reliable domain name server will stop the problem happening.
- Add a "." to the end of your hostnames when typing into the browser (for example, "google.com.au."). The trailing "." prevents the domain name searching from kicking in.
- If you're able, configure firewalls to drop packets from the name servers at "com.com.au" and "au.com.au".
Other things can be explained:
- It appeared to be an "Optus problem" at one stage because their domain name servers are occasionally overloaded and therefore slow. The Optus domain ends in "com.au" and so the domain name search would go all the way back to ".com.au". TPG seems to have similar issues.
- I couldn't reproduce the problem at work because my domain name there is "work.com". The resolver is smart enough not to search as far back as ".com" -- it just missed the case where a country domain has subclassifications (such as ".com.au", ".co.nz" or ".co.uk"). That's the limitation to the "counting dots" method of deciding how far to walk back.
- Switching to OpenDNS would appear to solve the problem because the resolver didn't need to start a domain name search if it got the right answer right away.
- Flushing the DNS cache would appear to solve the problem because it's only occasionally that DNS replies get lost. You have a good chance on your second attempt of getting the right address.
Friday 13 March 2009
Monitoring Rails builds with CruiseControl.rb and CCTray
More for my own memory than anything else...
CruiseControl.NET comes with a tool called CCTray that gives you a handy way of monitoring the build status of multiple CruiseControl environments. It works out of the box with other CruiseControl.NET installations but needs a little trick to monitor the Ruby and Java versions (why we need the same app implemented three times is a subject for a rant one day I'm sure...).
For Ruby on Rails projects, set the monitoring URL in CCTray to this:
Cruise Control for Java is similar, but different ('natch):
CruiseControl.NET comes with a tool called CCTray that gives you a handy way of monitoring the build status of multiple CruiseControl environments. It works out of the box with other CruiseControl.NET installations but needs a little trick to monitor the Ruby and Java versions (why we need the same app implemented three times is a subject for a rant one day I'm sure...).
For Ruby on Rails projects, set the monitoring URL in CCTray to this:
http://hostname.of.cruisecontrol.rb:3333/XmlStatusReport.aspxIt's not a real ASPX page but it returns XML that CCTray is expecting.
Cruise Control for Java is similar, but different ('natch):
http://hostname.of.cruisecontrol:3333/dashboard/cctray.xmlHad trouble Googling that. :-)
Monday 9 March 2009
Keep yourself logged in to a website with anti-idle
At $work I need to use a time sheet application which has a session timeout feature. I want a way to stay "logged in". So I've conceived a little plug-in for my personal web developer's proxy that will re-load certain web pages periodically in the background.
Could work like this:
[...]
Could work like this:
- Start your personal proxy with the anti-idle plug-in in the chain (below).
- In your browser, go to the page you want to periodically re-load.
- At the end of the URL, append a CGI argument. For example you could append "?ttt_anti_idle=300" to reload the page every 5 minutes. If there are already CGI arguments in the URL just append: "&ttt_anti_idle=300".
- Load the new URL you've just typed. The anti-idle plug-in will strip out the extra argument you've appended prior to giving the URL to the "real" server.
- The anti-idle plug-in monitors its stream for "ttt_anti_idle" arguments and builds a list of pages to reload at certain intervals. It discards the result of course.
Here's how I imagine I'd set up the pipeline:
$ proxy | anti_idle --use_cgi=ttt_anti_idle | respond
[...]
Friday 6 March 2009
Initial Load Values for Nagios Load Checks (Cheat Sheet)
I've put together a cheat sheet to show how you might want to initially configure your Nagios load checks. The thinking behind these initial values is set out in Tuning Nagios Load Checks.
General notes:
| Use | OS | Cores | Warning | Critical | Notes |
|---|---|---|---|---|---|
| CMS (Teamsite) | Solaris | 1 | 10,7,5 | 20,15,10 | Testing shows this app to be responsive up until these loads. |
| Web Server | Linux | 2 x 4 | 16,10,4 | 32,24,20 | Web servers are paired, so want to know if reaching 50% capacity regularly. Testing shows performance degradation from a load of 20. |
| DB Server | Linux | 2 x 4 | 16,10,4 | 32,24,20 | Same hardware, different use. Nevertheless, using same thresholds. |
| Nagios | Linux | 1 x 2 | 6,4,2 | 12,10,7 | Small box, paired with backup. |
General notes:
- The UNIX servers (particularly the Sun SPARC ones) seem to be able to stay up and responsive even under heavy load. And they don't count processes waiting for I/O in their load counts the way Linux does. I have no explanation for this. :-)
- We track these loads over time to predict demand growth for capacity planning -- the thresholds are not a long term goal but rather a short term alert threshold.
- Transaction or revenue-earning web servers might have lower thresholds because of the different commercial implications of performance degradation. YMMV.
For more information on the Nagios check_load command, see Tuning Nagios Load Checks.
No more stupid YouTube comments
Prompted by Mark Damon Hughes' Stupid Comments Be Gone I wrote a small script that took YouTube HTML in on stdin, stripped out the comments, and spat the remainder out on stdout (Mark's trick uses CSS to hide them).
Now I can do this:
And lo! Works in all browsers. :-)
Breaking it down:
I sometimes wonder if anyone else in the world would find a personal, hackable proxy useful.
Now I can do this:
$ proxy | connect | kill_youtube_comments | respond
[...]
And lo! Works in all browsers. :-)
Breaking it down:
- The proxy command listens on port 8080 (I configure my browser to proxy to localhost:8080). It spits all requests it sees to stdout.
- The connect command reads a HTTP request on stdin, connects to the remote server, fetches the content, and spits a HTTP request on stdout.
- The kill_youtube_comments command reads in HTML and strips out the div that contains YouTube comments.
- The respond command reads a HTTP response and sends that (via named pipe) back to the proxy command so that it can return it to the browser.
I sometimes wonder if anyone else in the world would find a personal, hackable proxy useful.
Friday 16 January 2009
Using Blogger's new Import Blog function to import an RSS-based blog
[UPDATE: I've released the code that I referred to below as a GitHub Gist.]
I've been playing with Blogger's Import Blog feature , made available in Blogger in Draft last year.
Google explicitly state that only Blogger exported blogs are supported. Blogger exports its blogs in Atom format. I thought perhaps that I could convert an RSS feed to Atom and then import that into Blogger and thereby move some old non-Blogger blogs over to Blogger.
Alas, no joy! The Blogger Import tool is quite fussy about its Atom. For example, if you export a blog in Atom format, and then run that through an XML formatting tool and re-import, you'll find that Blogger complains about the uploaded file.
However, I've kept at it, and now have a simple script that can take an RSS feed and convert it to an Atom format that Blogger seems happy with. It's not quite there -- a few posts are silently dropped for reasons I haven't figured out yet. I'm toying with the idea of eventually releasing it. Of course, I'm not the only one .
via hissohathair.blogspot.com
I've been playing with Blogger's Import Blog feature , made available in Blogger in Draft last year.
Google explicitly state that only Blogger exported blogs are supported. Blogger exports its blogs in Atom format. I thought perhaps that I could convert an RSS feed to Atom and then import that into Blogger and thereby move some old non-Blogger blogs over to Blogger.
Alas, no joy! The Blogger Import tool is quite fussy about its Atom. For example, if you export a blog in Atom format, and then run that through an XML formatting tool and re-import, you'll find that Blogger complains about the uploaded file.
However, I've kept at it, and now have a simple script that can take an RSS feed and convert it to an Atom format that Blogger seems happy with. It's not quite there -- a few posts are silently dropped for reasons I haven't figured out yet. I'm toying with the idea of eventually releasing it. Of course, I'm not the only one .
via hissohathair.blogspot.com
Thursday 15 January 2009
Oh! Look! Time_t party coming!
At 10:30:31 on Friday the 14th of February this year (Sydney time) the UNIX epoch time will be "1234567890".
Time for a time_t party !
via hissohathair.blogspot.com
Time for a time_t party !
via hissohathair.blogspot.com
Subscribe to:
Posts (Atom)